Clustering
K-means Algorithm
For a given dataset without any labels , clustering is the task of finding a partition of the data into subsets (clusters) such that the data points in the same cluster are more similar to each other than to those in other clusters. For this purpose, we usually use the k-means algorithm.
The first loop gives us the centroid that is closest to each data point . The second loop updates the centroid for each cluster as the mean of all data points assigned to that cluster.
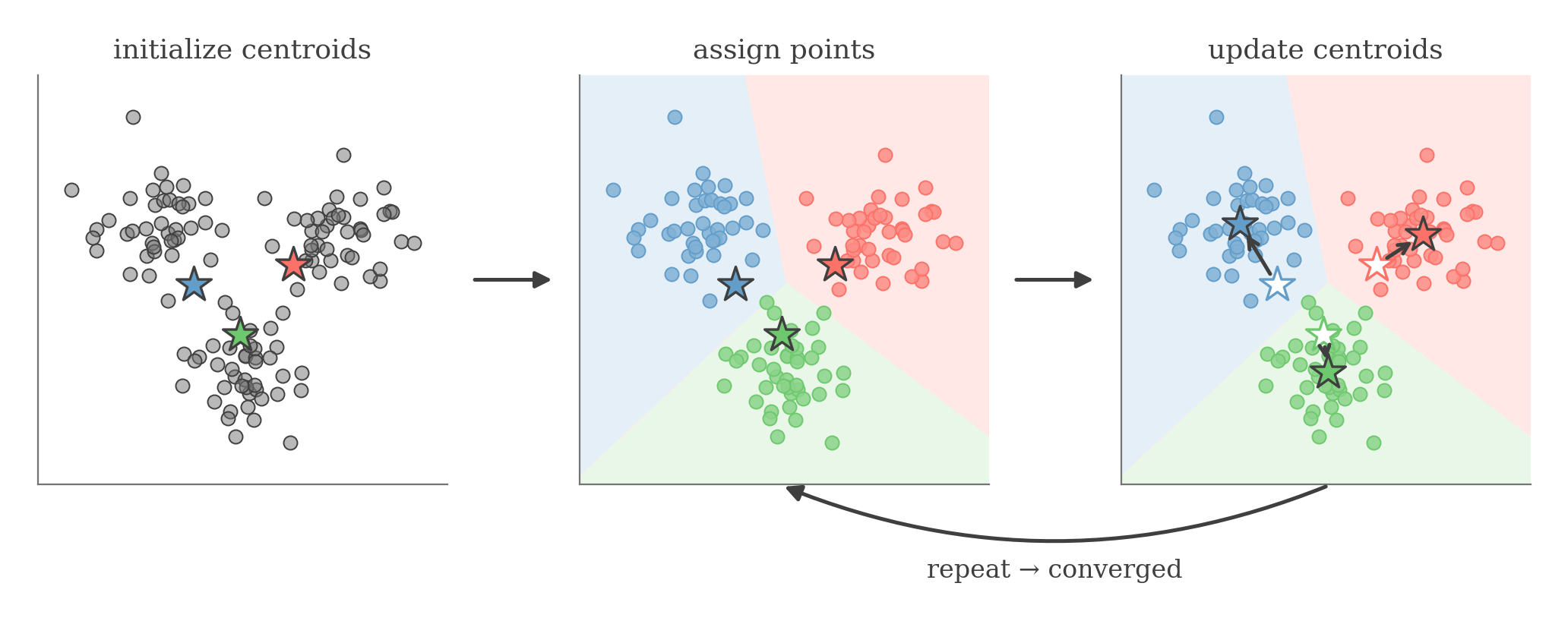
One round on three clusters. From random centroids (left), each is assigned to its nearest centroid, carving the plane into Voronoi regions (middle); each then moves to its points' mean (right), alternating until assignments stop changing.
The distortion function (that measures the sum of the squared distances between each data point and its assigned centroid) can be written as:
In each step of the k-means algorithm, either decreases or stays the same. Therefore, the algorithm is guaranteed to converge. However, the convergence is not guaranteed to reach a global minimum since is non-convex.
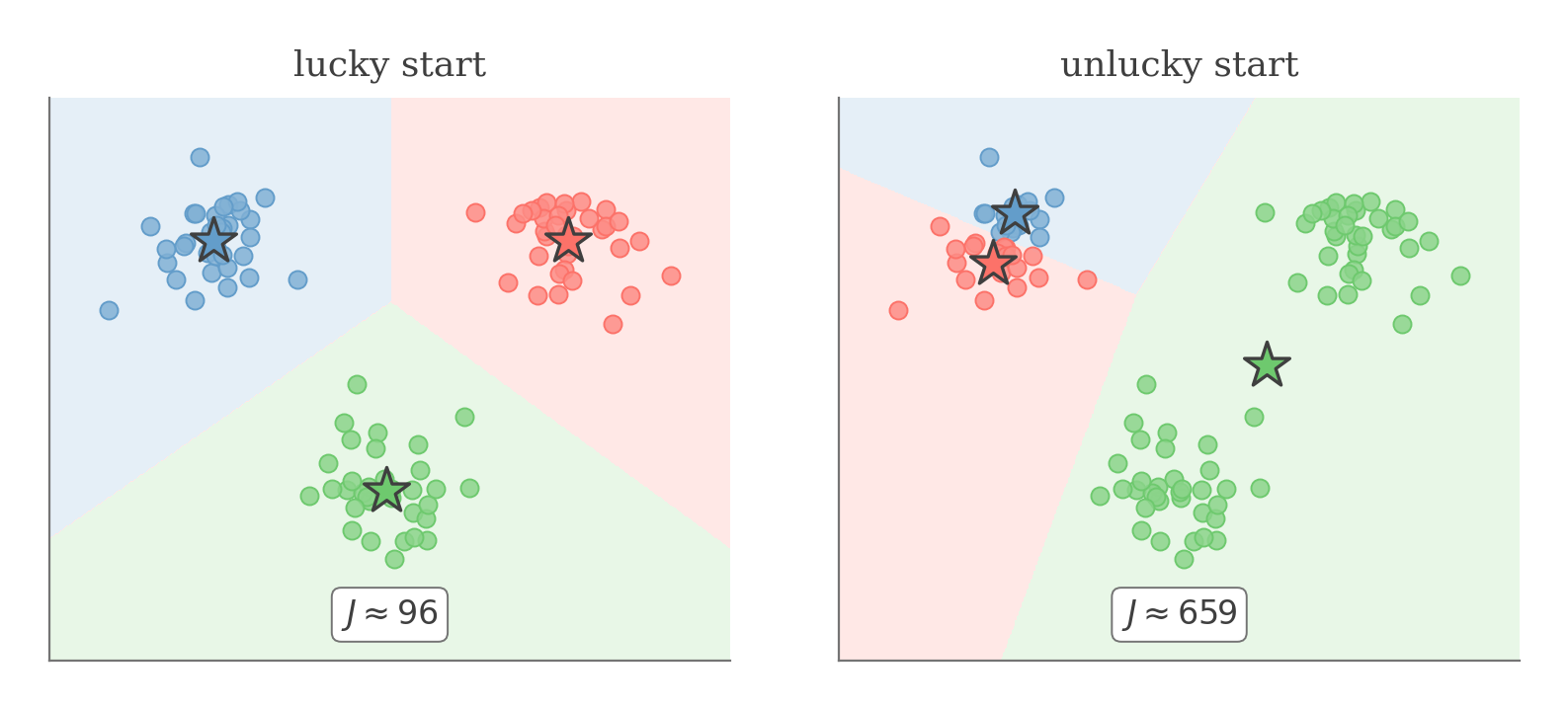
A lucky initialization recovers the three clusters (, left); an unlucky one splits one cluster and merges two others, a far worse optimum (, right). In practice we re-run and keep the lowest .
Please use a larger screen
This content is best viewed on a laptop or desktop device.